JS学习一波
最近看了一下《JavaScript高级编程》、《Node深入浅出》,挑了一些自己认为重要的、不熟悉的地方做了一下笔记。
《Node深入浅出》笔记
起源
期初:一个外国人”Ryan Dahl”想写一个高性能的Web服务器,在他失败了几次以后,找到了几个要点:事件驱动、异步 I/O。挑语言的时候,经历了这样的选择:
- C语言的开发门太高,不会有ܹ多的开发者能把它用于日常的务开发,放弃了。
- Haskell(我不知道这个是啥)”Ryan Dahl”觉得这个好难,放弃了。
- Ruby性能不咋滴,放弃了。
相比之下JavaScript:
比 C的开发门槛低;
导入异步I/O库没有啥压力;
Chrome引擎V8牛皮(高性能);
符合事件驱动。
因此JavaScript成为了Node的实现语言。而不是说直接想JavaScript写后端,这中间是有这样一个过程的。
特点
- 异步I/O(利用回调函数)
- 单线程:
- Node是单线程,JavaScript和其他线程不能共享任何状态。所以没有死锁,没有上下文切换
- 不能利用多核CPU
- 大量计算占用CPU会导致无法调用异步I/O (长时间的计算,将导致CPU时间片不能释放)
- 如果有大计算阻塞UI,可以使用Web Workers工作线程。但只能通过消息传递的方式来传递结果,但是工作线程不能访问到UI主线程。我的理解是:C#、Java等主线程和子线程常用的思想是不能在这里实现。
CommonJS
之前有人问我CommonJS 和 es 有啥区别,我是不知道CommonJS 和 es有啥区别。刚好看到这里,如下图:

因为ECMAScript仅定了部分核心代码,对于文件系统, I/O等库没有相关标准。缺点有如下:
- 没有模块系统
- 标准库较少
- 没有标准接口
缺乏包管理系统(没有自动加载能力和安装依赖能力)
Node借鉴 CommonJS的Modules规范实现了一个模块系统: NPM。一个模块文件中有:require、exports、module三个变量
Node性能不够的时候呢,可以编写c/c++扩展模块
异步I/O
Node是单线程的,这里的单线程仅仅只是JavaScript执行在单线程中。在Node中,无论是linux还是Windowsࣰ中,内部完成I/O任务的是另有线程的。
事件循环:在进程启动时, Node会会创建一个类似于while(true)的循环,判断是否有事件待处理,有就取出事件和相关回调函数。如果存在关联的回调函数,就执行他们,然后进入下一个循环。没有事件就退出进程。如下图:

- 浏览器采用了类似的机制。都有对应的观察者。在Node中,网络请求、文件I/O都有自己的观察者。事件循环从观察者中读取数据。(给我的感觉是,有观察者类似于队列,然后一个循环不断从队列里头去读数据,有点读写分离的感觉)
异步编程
- promise是咋整的,这里就不展开了,自己看吧。
内存控制
V8堆内存的最大值在64位系统上为1464 MB, 32系统则为732 MB
Scavenge算法
Scavenge算法进行垃圾回收。它将堆内存一分为二,每一部分空间称为 semispace。在这两个 semispace 空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的 semispace 空间称为 From 空间,处于闲置状态的空间称为 To 空间。当我们分配对象时,先是在 From 空间中进行分配。当开始进行垃圾回收时,会检查 From 空间中的存活对象,这 些存活对象将被复制到 To 空间中,而非存活对象占用的空间将会被释放。完成复制后,From 空 间和To空间的角色发生对换。 简而言之, 在垃圾回收的过程中, 就是通过将存活对象在两个 semispace 空间之间进行复制。
Scavenge算法通过牺牲空间换时间的算法非常适合生命周期短的新生代,但是,当一个对象经过多次复制,生命周期较长的时候或则To空间不足的时候,对象会被分配到进入到老生代中,需要采用新的算法进行垃圾回收。
Mark-Sweep算法
Mark-Sweep 在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以看出,Scavenge 中只复制活着的对象,而 Mark-Sweep 只清理死亡对象。
Mark-Sweep 在进行一次标记清除回收后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,因为很可能出现需要分配一个大对象的情况,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。Mark-Compact 对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存Mark-Compacts算法
Mark-Compacts算法:mark-compact对于标记死亡对象的整理过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。(简单理解–整理活着对象向一段移动,另一端直接清空)
其他:GC无法立即回收内存中的闭包和全局变量
Buffer对象并非通过V8分配,在Node需要处理网络流或者文件I/O流的时候,可能操作字符串不能满足传输,可以用Buffer。Buffer属性指向的是C++层面上的Buffer对象,所以不在V8堆中。
Session因为V8内存的问题,不适合放在内部维护,可以放在外部,比如说:redis、Memcached中。
《JavaScript高级编程》笔记
面向对象程序设计
因为接触的多数是面向对象的语言,对js里面的面向对象的实现不是很了解,故一个记录。
原型的关键
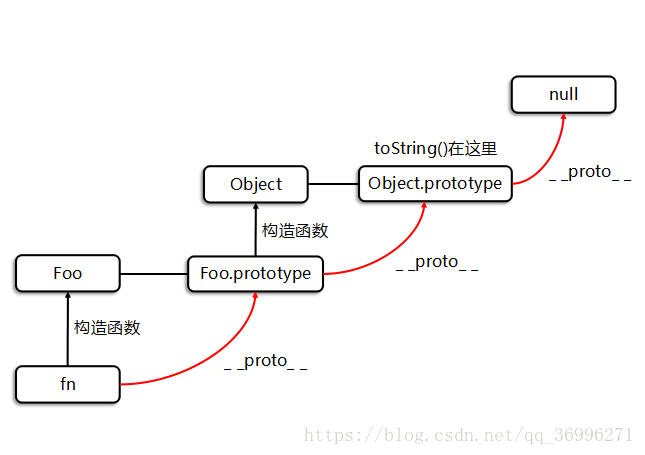
- 所有的引用类型(数组、函数、对象)可以自由扩展属性(除null以外)
- 所有的引用类型都有一个’_ _ proto_ _’属性(也叫隐式原型,它是一个普通的对象)
- 所有的函数都有一个’prototype’属性(这也叫显式原型,它也是一个普通的对象)
- 所有引用类型,它的’_ _ proto_ _’属性指向它的构造函数的’prototype’属性
- 当试图得到一个对象的属性时,如果这个对象本身不存在这个属性,那么就会去它的’_ _ proto_ _’属性(也就是它的构造函数的’prototype’属性)中去寻找
prototype的作用:如果我们要通过Foo()来创建很多个对象,我们创建出来的每一个对象里面都有showName和showAge方法,会占用很多的资源。而通过原型来实现的话,只需要在构造函数里面给属性赋值,而把方法写在Foo.prototype属性里面。每个对象都可以使用prototype属性里面的showName、showAge方法,并且节省资源。
1
2
3
4
5
6
7
8
9
10function Foo(name,age){
this.name=name;
this.age=age;
this.showName=function(){
console.log("I'm "+this.name);
}
this.showAge=function(){
console.log("And I'm "+this.age);
}
}如果使用prototype的话,将变成这样子:
1
2
3
4
5
6
7
8
9
10
11
12
13function Foo(name,age){
this.name=name;
this.age=age;
}
Foo.prototype={
// prototype对象里面又有其他的属性
showName:function(){
console.log("I'm "+this.name);//this是什么要看执行的时候谁调用了这个函数
},
showAge:function(){
console.log("And I'm "+this.age);//this是什么要看执行的时候谁调用了这个函数
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 构造函数
function Foo(name,age){
this.name=name;
this.age=age;
}
Object.prototype.toString=function(){
//this是什么要看执行的时候谁调用了这个函数。
console.log("I'm "+this.name+" And I'm "+this.age);
}
var fn=new Foo('小明',19);
fn.toString(); //I'm 小明 And I'm 19
console.log(fn.toString===Foo.prototype.__proto__.toString); //true
console.log(fn.__proto__ ===Foo.prototype)//true
console.log(Foo.prototype.__proto__===Object.prototype)//true
console.log(Object.prototype.__proto__===null)//true创建对象的方式
工厂模式(不能对象的类型)
1
2
3
4
5
6
7
8
9
10
11function createPerson(name, job) {
var o = new Object()
o.name = name
o.job = job
o.sayName = function() {
console.log(this.name)
}
return o
}
// person1 为 Object
var person1 = createPerson('Jiang', 'student')构造函数模式(每个方法都要在每个实例上重新创建一次)
1 | function Person(name, job) { |
- 原型模式 (原型的好处是可以让所有的实例对象共享它所包含的属性和方法,引用类型值会有问题)
1
2
3
4
5
6
7
8function Person() {
}
Person.prototype.name = 'Jiang'
Person.prototype.job = 'student'
Person.prototype.sayName = function() {
console.log(this.name)
}
var person1 = new Person()
person2中没有加friends的,输出也是有的1
2
3
4
5
6var person1 = new Person()
var person2 = new Person()
person1.friends.push('Van')
console.log(person1.friends) //["Shelby", "Court", "Van"]
console.log(person2.friends) //["Shelby", "Court", "Van"]
console.log(person1.friends === person2.friends) // true
所以,对于引用类型的,尽量是放在对象里头。1
2
3
4
5
6
7
8
9
10
11
12
13function Person(name) {
this.name = name
this.friends = ['Shelby', 'Court']
}
Person.prototype.sayName = function() {
console.log(this.name)
}
var person1 = new Person()
var person2 = new Person()
person1.friends.push('Van')
console.log(person1.friends) //["Shelby", "Court", "Van"]
console.log(person2.friends) // ["Shelby", "Court"]
console.log(person1.friends === person2.friends) //false
- 动态原型模式 ,态原型模式将所有信息都封装在了构造函数中,初始化的时候,通过检测某个应该存在的方法时候有效,来决定是否需要初始化原型。只有在sayName方法不存在的时候,才会将它添加到原型中。这段代码只会初次调用构造函数的时候才会执行。
1 | function Person(name, job) { |
寄生构造函数模式,构造函数如果不返回对象,默认也会返回一个新的对象,通过在构造函数的末尾添加一个return语句,可以重写调用构造函数时返回的值
1
2
3
4
5
6
7
8
9
10
11function Person(name, job) {
var o = new Object()
o.name = name
o.job = job
o.sayName = function() {
console.log(this.name)
}
return o
}
var person1 = new Person('Jiang', 'student')
person1.sayName()稳妥构造函数模式: 稳妥构造函数模式和寄生模式类似,有两点不同:一是创建对象的实例方法不引用this,而是不使用new操作符调用构造函数
1
2
3
4
5
6
7
8
9
10
11function Person(name, job) {
var o = new Object()
o.name = name
o.job = job
o.sayName = function() {
console.log(name)
}
return o
}
var person1 = Person('Jiang', 'student')
person1.sayName()